چرا مغزهای رباتی به نماد نیاز دارند
برای ساختن هوش مصنوعی، هم به یادگیری عمیق و هم به دستکاری نمادها نیاز خواهیم داشت.

نوشته ی گری مارکوس[1]
به نظر میرسد امروزه عبارت “هوش مصنوعی” به زبان همه افتاده است، از الون ماسک گرفته تا هنری کیسینجر. حداقل یکدوجین از کشورها ابتکارات مهمی در عرصهی هوش مصنوعی به خرج دادهاند و کمپانیهایی همچون گوگل یا فیسبوک درگیر رقابتی سخت برای جذب استعدادهای این حوزه هستند. از سال 2012 عملاً تمام توجهات در این عرصه به یک شیوهی خاص معطوف بوده که با عنوان «یادگیری عمیق»[2] معروف است، یک روش آماری که از مجموعههایی از “نورون”های سادهسازیشده به منظور شبیهسازی به پویایی موجود در دستههای بزرگ و پیچیدهی دادهها بهره میبرد. یادگیری عمیق در تمامی حوزهها از تشخیص گفتار گرفته تا شطرنج کامپیوتری و نشانهگذاری خودکار عکسها به پیشرفتهایی دست یافته است. و احتمالاً برخی با توجه به این پیشرفتها چنین میپندارند که دیگر فاصلهی چندانی با “فراهوش” –دستگاههایی که هوش بسیار بالاتری نسبت به انسانها دارند– نداریم.
اما واقعیت ماجرا این نیست. این که یک دستگاه بتواند هجاهای درون یک جمله از شما را تشخیص دهد با اینکه که واقعاً بتواند معنای جملات شما را بفهمد، فرق دارد. سیستمی مثل الکسا میتواند یک درخواست ساده مثل “چراغها را روشن کن” را متوجه شود، اما با برقرار کردن یک مکالمهی معنادار فاصلهی زیادی دارد. همچنین رباتها میتوانند زمین را برایتان جارو بکشند، اما هوش مصنوعیای که این قابلیتها را بهشان داده همچنان ضعیف است و این رباتها با نقطهای که آنقدر هوشمند (و قابل اعتماد) بشوند که از کودکان شما نگهداری کنند، فاصلهی زیادی دارند. هنوز کارهای بسیاری وجود دارد که انسانها قادر به انجام آنها هستند اما از عهدهی ماشینها ساخته نیست.

اختلافنظرهای بسیاری بر سر گام بعدی هوش مصنوعی وجود دارد. من به خوبی از این نکته آگاهم: چون طی سه دههی گذشته از زمانی که تحصیلات تکمیلیام را در مؤسسهی فناوری ماساچوست آغاز کردم و مطالعاتم را با همراهی یک دانشمند الهام بخش علوم شناختی با نام استیون پینکر[3] شروع کردم، متناوباً درگیر جروبحثهایی راجع به ماهیت ذهن انسان و بهترین راه برای ساختن هوش مصنوعی بودهام. من گهگاه دربرابر روشهایی مثل یادگیری عمیق (و اسلاف این روش که در گذشته به کار میرفتهاند) موضعی برخلاف بابمیل عموم گرفتهام که این روشها برای به چنگ آوردن غنایی که در ذهن انسانهاست، کفایت نمیکنند.
هفتهی پیش یکی از این جروبحثهایی که متناوباً تکرار میشود، به شکلی عمده و بطور غیر منتظرهای در گرفت و به یک طوفان توییتری عظیم منجر شد که شماری از چهرههای برجسته را هم درگیر خود ساخت، چهرههایی اعم از یان لِکُن[4]، یکی از بنیانگذاران یادگیری عمیق و رئیس بخش هوش مصنوعی در فیسبوک، و (بطور مختصری) جف دین[5] که رئیس بخش هوش مصنوعی در گوگل است، و همینطور جودیا پرل[6]، یکی از برندگان جایزهی تورینگ از دانشگاه کالیفرنیا (لس آنجلس).
وقتی دیدم دیگر ۱۴۰ کاراکتر حق مطلب را ادا نمیکند، سعی کردم یک گام عقبتر بروم و توضیح بدهم که چرا یادگیری عمیق ممکن است کافی نباشد و در کجا باید به دنبال ایدهی دیگری باشیم که بتواند با یادگیری عمیق ترکیب شود و هوش مصنوعی را به سطحی جدیدتر رهنمون سازد. آنچه در ادامه میآید نوشتاریست با اندکی جرح و تعدیل که دیدگاه شخصی مرا نسبت به این بحث در کلیت خود نشان میدهد.
همه چیز از آنجا آغاز شد که یکی از مصاحبههای یوشوا بنگیو[7] (یکی از پیشگامان عرصهی یادگیری عمیق) را در مجلهی تکنولوژی ریویو[8] مطالعه میکردم. در حالی که سایر مخترعین اغلب در مورد اختراعات خود اغراق میکنند، بنگیو کشف خود را ناچیز جلوه داده بود و در عوض به بر برخی از مسائل هوش مصنوعی اشاره کرده بود که باید به آنها پرداخت و چنین گفته بود:
فکر میکنم ما باید چالشهای اساسی هوش مصنوعی را در نظر بگیریم و به پیشرفتهای کوتاهمدت و تدریجی دلخوش نباشیم. بحث من این نیست که باید یادگیری عمیق را به فراموشی سپرد. برعکس، قصد من آن است که چیزی به آن اضافه کنم. اما ما باید بتوانیم هوش مصنوعی را به نحوی بسط دهیم که اموری همچون استدلال، یادگیری قوانین عِلّی و را نیز انجام دهد و به قصد یادگیری و کسب اطلاعات در جهان جستجو کند.
من با تکتک این کلمات موافق بودم و به نظرم خیلی شگفتآور بود که بنگیو این سخنان را به شکل کاملاً علنی بیان کرده بود. آنچیزهایی که باعث شگفتی من شده بودند عبارت بودند از:
(الف) تغییر مهم در نگرش یا حداقل در چارچوب بندی، به نسبت با نحوهی چارچوببندی امور توسط حامیان یادگیری عمیق در سالهای گذشته (پایین را ببینید)،
(ب) حرکت در مسیری که مدتها حامیاش بودم،
و (پ) این که این موضوع توسط بنگیو مطرح شده بود.
اینچنین بود که این مصاحبه را توییت کردم و فقط انتظار چند ریتوییت داشتم. اما تقریباً بلافاصله پس از این توییت، یک طوفان توییتری به راه افتاد.
این توییت من است که احتمالاً در میانهی طوفانی که از پیآمد به دست فراموشی سپرده شد:
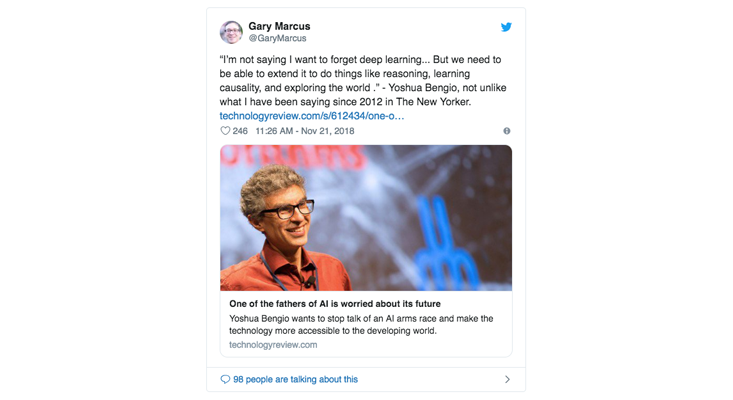
(متن توییت: “بحث من این نیست که باید یادگیری عمیق را به فراموشی سپرد… اما ما باید بتوانیم هوش مصنوعی را به نحوی بسط دهیم که بتواند اموری همچون استدلال، یادگیری قوانین علی و جستجو در جهان را انجام دهد.” یاشوا بینگو؛ این گفته بیشباهت به آنچه من در سال 2012 در نیویورکر نوشتم نیست.)
جهت اطلاع و مقایسه، این هم گفتهای است که – با همزمانی ترسناکی – تقریباً بطور دقیق شش سال قبل در 25 نوامبر 2012 بیان کرده بودم:
یادگیری عمیق کار مهمیست که فوراً کاربرد عملی پیدا میکند.
…
اگر واقعنگرانه مسائل را ببینیم، یادگیری عمیق صرفاً بخشی از چالش بزرگترِ ساختن ماشینهای هوشمند است. این روش فاقد سازوکارهایی برای بازنمایی روابط عِلّی است (مثلا بین بیماری و علائم بیماری)، و احتمالاً در اکتساب ایدههای انتزاعی مثل “همشیر” یا “همسان با” به مشکل برمیخورد. این روش دارای هیچ سازوکار مشخصی برای انجام استنتاجهای منطقی نبوده و همچنین هنوز قادر به یکپارچهسازی دانش انتزاعی (مثلاً اطلاعات در مورد چیستی اشیاء، علت وجود آنها و کاربرد معمولشان) نمیباشد. قدرتمندترین سیستمهای هوش مصنوعی… از روشهایی مثل یادگیری عمیق صرفاً به عنوان یک عنصر از مجموعهی پیچیدهای از روشها اعم از روش آماری استنتاج بیزی[9] و استدلال قیاسی بهره میگیرند.
من هنوز سر حرفم هستم. تا جایی که میدانم (و ممکن هم هست اشتباه کنم) این اولین باری بود که کسی میگفت یادگیری عمیق فینفسه علاج نهایی به حساب نمیآید. بر اساس آنچه افرادی همچون پینکر و من در مورد یک نسل قدیمیتر از الگوهای پیشین کشف کرده بودیم، قیل و قالی که حول یادگیری عمیق داشت شکل میگرفت به نظر واقعبینانه نمیآمد. بنگیو هم شش سال بعد موبهمو همین را گفت.
بعضی ها از توییت خوششان آمد و بعضی هم خوششان نیامد. واکنش یان لکن شدیداً منفی بود. او در یک رشتهتوییت (به اشتباه) مدعی آن شد که من از یادگیری عمیق متنفرم و چون شخصاً توسعهدهندهی الگوریتم نیستم حق انتقاد ندارم؛ برای این که معیار بهتری برای قضاوت داشته باشید در نظر بگیرید که او همچنین گفت که اگر من کوچکترین بویی هم از یادگیری عمیق برده باشم، این امر حتماً در همین چند روز اخیر و در فضای بحث توییتریمان اتفاق افتاده است (که این هم اشتباه بود).
به باور من، با اندیشه در مورد آنچه در آن بحث گفته شد و آنچه گفته نشد (و آن سخنانی که معمولاً در چنین بحثهایی مورد توجه یا بی توجهی قرار میگیرد) و با توجه به آنکه هنوز یادگیری عمیق محل مناقشه است، میتوان چیزهای زیادی آموخت.
باید در مورد چند سوءتفاهم توضیح بدهم: من اصلاً از یادگیری عمیق متنفر نیستم. ما آن را در جدیدترین شرکت خودمان به کار گرفتهایم (من مدیر عامل و یکی از بنیانگذاران این کمپانی بودم) و فکر میکنم که باز هم از آن استفاده خواهم کرد؛ باید دیوانه باشم که نادیدهاش بگیرم. به نظر من – و این را برای اطلاع عموم میگویم و میتوانید این گفته را از قول من نقل کنید– یادگیری عمیق برای بعضی مسائل ابزاری بسیار معرکه است، به ویژه آن دسته از مسائل که شامل طبقهبندی ادراکی هستند مثل تشخیص هجاها و اشیاء. ولی علاج نهایی هم نیست. در بحثی که در دانشگاه نیویورک با لکن داشتم، کارهای قدیمی تر لکن در مورد پیچش را مورد تحسین قرار دادم چون ابزاری که او ساخته یک ابزار فوقالعاده قدرتمند است. ضمناً من از اولین مطلبی که به طور خاص در مورد یادگیری عمیق نوشتم، برای این روش قدری (اما نه خیلی زیاد) ارزش قائل شدهام: در مجلهی نیویورکر در 2012؛ همچنین در مقالهای که در ژانویه ی 2018 با عنوان یادگیری عمیق: یک مقالهی انتقادی ارزشیابی نوشتم، واضحاً گفتهام که “من عقیده ندارم که باید از یادگیری عمیق دست بشوییم”، و در موارد متعددی در فاصلهی زمانی بین این دو مقاله هم سخنان مشابهی را مطرح نمودهام. لِکُن مکرراً و علناً به اشتباه مرا فردی به تصویر کشیده که به تازگی از کاربرد یادگیری عمیق آگاه شده است، و این سخن درستی نیست.
ادعای لکن در مورد این که من نباید اجازهی اظهار نظر داشته باشم هم ادعایی مضحک است: علم محتاج منتقدان است (خود لکن هم انتقادات بجایی از یادگیری تقویتی عمیق و محاسبه ی نورومورفیک[10] مطرح کرده است). و هرچند من شخصاً مهندس الگوریتم نیستم، اما انتقادم تا به اینجای کار از ارزش پیشبینی ماندگاری برخوردار بوده است. برای مثال آزمایشهایی که من در مورد روشهای ماقبل یادگیری عمیق انجام دادهام و نتایج آن برای اولین بار در سال 1998 منتشر شد، همانگونه که الگوهای مدرنی که افرادی همچون برندون لیک[11] و مارکو بارونی[12] و خود بنگیو ارائه دادهاند نشان میدهد، هنوز هم معتبرند. وقتی به جای رفع موارد انتقادبرانگیز سعی بر خاموش کردن منتقدان خود با یک رشتهتوییت داشته باشد و سیاست را جایگزین تحقیق علمی کند، مرتکب خطایی جدی میشوید.
اما لکن در مورد یک موضوع حق دارد؛ من از یک چیز تنفر دارم. آنچه از آن تنفر دارم این است: این تصور که یادگیری عمیق هیچ حدود معینی نداشته و قادر است به تنهایی ما را به هوش عمومی رهنمون کند، فقط لازم است اندکی زمان و دادهی بیشتری به آن بدهیم. این نظری است که در سال 2016 توسط اندرو نِگ[13]مطرح شد، کسی که هدایت پروژه ی google brain و گروه هوش مصنوعی بایدو را بر عهده داشته است. نگ چنین گفت که هوش مصنوعی، که عمدتاً منظور از آن یادگیری عمیق است، «یا اکنون و یا در آیندهای نزدیک» قادر خواهد بود «تمام تکالیف ذهنی» که یک انسان میتواند انجام دهد را «با کمتر از یک ثانیه فکر کردن» به انجام برساند.
عموماً – اما نه همیشه – انتقاداتی که نسبت به یادگیری عمیق مطرح میشود، یا نادیده گرفته میشود و یا در اغلب اوقات با حملهی شخصی پاسخ داده میشود. هرگاه فردی به این نکته اشاره کند که یادگیری عمیق ممکن است حد کاربرد معین و محدودی داشته باشد، همیشه افرادی مثل جرمی هاوارد[14]، رئیس سابق بخش علوم در کَگِل[15]پیش می آیند تا به ما بگویند که این تصور که یادگیری عمیق موضوعی اغراق شده است، خود ایدهای اغراقآمیز است. رهبران حوزهی هوش مصنوعی از جمله لکن، بطور دوپهلویی میپذیرند که باید حدودی وجود داشته باشد اما ندرتاً (و به این خاطر است که گزارش جدید بنگیو اهمیت زیادی داشت) به طور دقیق مشخص میکنند که این حدود کدامند و صرفا به تصدیق ماهیتِ داده خواهِ این عرصه اکتفا مینمایند.
برخی دیگر مایلند از ابهامِ موجود در مورد جعبه سیاه یادگیری عمیق به عنوان اهرمی در خدمت این ادعا استفاده کنند که اصلاً حدود مشخصی در کار نیست. برای مثال هفته ی گذشته تام دیتریش[16]، یکی از بنیانگذاران یادگیری ماشینی در پاسخ به پرسشی در رابطه با قلمرو و محدوده ی یادگیری عمیق چنین گفت:
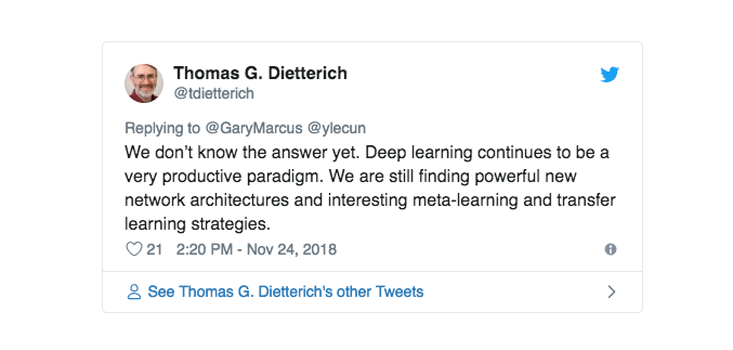
(متن توییت: هنوز پاسخ را نمیدانیم. یادگیری عمیق همچنان پارادایمی بسیار مولد است. ما همچنان در حال کشف ساختارهای جدید و قدرتمند شبکهای، و راهبردهای جالب توجهی برای فرایادگیری و انتقال یادگیری هستیم.)
البته سخن دیتریش به لحاظ فنی درست است؛ تابهحال هیچکس شواهد متقنی از حدود یادگیری عمیق ارائه نکرده و بنابراین هیچ پاسخ قطعیای وجود ندارد. همچنین نظر او در این باره که یادگیری عمیق به رشد خود ادامه میدهد نیز صحیح است. اما این توییت (که استدلالی که به دفعات شنیدهام را بیان میکند، از جمله از خود دیتریش) این حقیقت را نادیده میگیرد که ما شواهد محکمی دال بر وجود حداقل چند محدودیت در این حوزه در اختیار داریم. این محدودیتها عبارتند از: محدودیتهای به شکل تجربی بررسی شده در زمینه ی قابلیت استدلال، عملکرد ضعیف در حوزهی درک زمان طبیعی، آسیبپذیری نسبت به مثالهای خصمانه و غیره . (در انتهای این مقاله من نمونهای از این محدودیتها در عرصهی تشخیص شئ را مطرح خواهم کرد، حوزه ای که معمولا نقطه قوت یادگیری عمیق تصور میشود.)
به عنوان یک نمونهی دیگر، مقالهی معروفی که لکن، بنگیو و جفری هینتون را در نظر بگیرید[17]، سه نفری که بیش از سایرین در امر اختراع یادگیری عمیق دخیل بودهاند در سال 2015 در مجله ی نیچر[18]منتشر نمودند. مقالهی فوق با تفصیل فراوان به بررسی نقاط قوت یادگیری عمیق میپردازد. البته اکثر مطالب مذکور در آن مقاله صحیح است، اما مقالهی فوقالذکر تقریباً هیچ اشارهای به محدودیتهای یادگیری عمیق نمیکند تا خواننده هنگامی که خواندن آن را به پایان میبرد این تصور را پیدا کند که یادگیری عمیق ابزاری بسیار گستردهتر از آنچه در واقع هست می باشد. قسمت نتیجهگیری آن مقاله با اشاره به این که رقیب دیرین یادگیری عمیق – دستکاری نمادها/هوش مصنوعی کلاسیک – باید با مفهوم دیگری جایگزین شود، به این تصور دامن میزند – در بخشی از مقاله میخوانیم که: «به پارادایم های نوینی نیازمندیم که جایگزین دستکاری قاعده محورِ عبارات نمادین روی بُردارهای بزرگ شوند.» مؤخرهی متداول بسیاری از مقالات علمی – یعنی قسمت محدودیتها – هم اصلاً به چشم نمیخورد و این استنباط را تقویت میکند که افقهای یادگیری نامحدودند. به نظر میرسد پیامی که از این مقاله میتوان گرفت آن باشد که دستکاری نمادها بزودی به زبالهدان تاریخ افکنده خواهد شد.
رویکرد تأکید بر نقاط قوت بدون تصدیق محدودیتها، در مقاله ای که در سال 2017 از سوی شرکت هوش مصنوعی deep mind وابسته به گوگل درباره ی go منتشر شد، بیشتر به چشم میخورد. به نظر میرسد این مقاله نیز افقهای نامحدودی را برای یادگیری عمیق تقویت شده متصور میشود. مقالهی فوق به این نکته اشاره میکند که go یکی از دشوارترین مسائل در هوش مصنوعی است – «نتایجی که بدست آوردیم دقیقا نشان میدهند که بکارگیری یک رویکرد مبتنی بر یادگیری [عمیق] تقویتشدهی محض، کاملاً امکانپذیر است. حتی در چالشبرانگیزترین حوزهها” – و اشاره ای نمیشود که سایر مسائل دشوار، به لحاظ کیفی و ماهوی متفاوت بوده و ممکن است با بکارگیری این نوع روشها قابل فهم نباشند. برای مثال، اطلاعات در اغلب تکالیف نسبت به go از تکمیلیافتگی کمتری برخوردار است. من در جای دیگری با تفصیل بیشتر به این موضوع پرداختهام.
این به شدت مرا نگران میسازد که یک رشتهتوییت عمدتاً یا صرفاً بر نقاط قوت آخرین کشفیات خود تأکید مینماید و هیچ اشارهی علنی به نقاط ضعف احتمالی – که در حقیقت کاملاً هم تأیید شده هستند – نمیکند.
دیدگاه من این است: یادگیری عمیق واقعاً خوب است، اما در معنای عام خود برای عمل شناخت ابزار مناسبی نیست. یادگیری عمیق ابزاری برای طبقهبندی ادراکیست، یعنی وقتی هوش عمومی به مرحلهی بسیار تکاملیافتهتری برسد. نظر من در سال 2012 (که هیچگاه از آن بر نگشتم) آن بود که یادگیری عمیق باید بخشی از رویهی کاری در عرصهی هوش مصنوعی باشد، نه همهی کار: چنانکه در آن مقاله گفتم، باید آن را «صرفاً یک عنصر از مجموعه ای بسیار پیچیده» در نظر گرفت، و همانطور که در مقالهای در ژانویهی امسال نوشتم، «نه یک حلال همهی مشکلات، [بلکه صرفاً] یک ابزار در میان ابزارهای دیگر.» یادگیری عمیق هم، همچون هر چیز دیگری که در نظر بگیریم، ابزاری است با نقاط قوت و ضعف مشخص. این موضوع نباید کسی را شگفتزده کند.
وقتی اقدام به بدگویی از یادگیری عمیق میکنم به آن خاطر نیست که عقیده دارم باید آن را «تعویض» کرد (مقایسه کنید با لحن سرسختانهی هینتون، لکن و بنگیو در آن مقاله که بر اساس آن گویی هدف از بازی، مغلوب ساختن رویکردهای پیشین است)، بلکه به این دلیل که عقیده دارم:
(الف) در مورد آن اغراق شده (برای مثال رجوع شود به گفته اندرو نگ، یا کل ساختار مقاله ی 2017 deep mind در مجله ی نیچر)، و اغلب به نقاط قوت آن در مقایسه با محدودیتهای بالقوهاش توجه بسیار بیشتری میشود و
(ب) اغراق در مورد یادگیری عمیق، غالباً (هرچند نه عموماً) با یک خصومت نسبت به دستکاری نمادها ملازم است و این به نظرم یک خطای بنیادین در رابطه با راه حل نهایی هوش مصنوعی است.
به عقیدهی من این به مراتب محتملتر است که دو راهبرد مذکور – یادگیری عمیق و دستکاری نمادها – همزیستی داشته باشند، به این صورت که یادگیری عمیق ابعاد مختلف طبقهبندی ادراکی را انجام دهد و دستکاری نمادها، نقش اصلی را در استدلال مرتبط با دانش انتزاعی بر عهده بگیرد. معمولاً پیشرفتهایی که با کمک یادگیری عمیق در عرصهی هوش مصنوعی به عمل میآید را طوری تعبیر میکنند که گویی دیگر به دستکاری نمادها نیاز نداریم و این به نظر من اشتباهی بسیار بزرگ است.
خوب، حالا دستکاری نمادها چیست و چرا من اینطور سفت و سخت به آن چسبیدهام؟ ایدهی آن به نخستین روزهای پیدایش علوم کامپیوتری باز میگردد (و حتی دورتر، به پیدایش منطق صوری) و آن این است که: نمادها میتوانند جایگزین تصورات شوند و اگر این نمادها را دستکاری کنید قادر خواهید بود استنتاجهای صحیحی درمورد استنباط هایی که این نمادها جایگزین آنها شدهاند، انجام دهید. اگر بدانید که P یعنی Q، میتوانید از نا-Q استنتاج کنید که نا-P. اگر من به شما بگویم که پلانک یعنی کویگل، اما کویگل صحیح نیست، آنگاه میتوانید استنتاج کنید که پلانک صحیح نیست.
در کتابی که در سال 2001 با عنوان ذهن جبری[19] نوشتم، از موضعی درون سنت روانشناسان شناختی همچون آلن نیوول[20]، هرب سایمون[21] و استادم استیون پینکر توضیح دادهام که ذهن انسان (در زمره ابزارهایی که دارد)، دارای مجموعهای از سازوکارها برای بازنمایی دستههایی از نمادهای ساختاریافته است و این مجموعه شکل یک درختِ سلسلهمراتبی را دارد. همچنین با لحنی انتقادیتر این نکته را مطرح کردم که یک جزء اساسی از شناخت، قابلیت یادگیری روابط انتزاعی بیان شده در قالب متغیرهاست – یعنی همان کاری که وقتی معادله ای مثل x=y+2 را می آموزیم و سپس x را بر حسب مقداری که به y میدهیم بدست میآوریم، انجام میدهیم. فرایند دادن یک مقدار مشخص به y (مثلا 5) را الصاق[22] می نامند؛ فرایندی که طی آن مقادیر با سایر عناصر ترکیب میشود را میتوان یک عملیات[23] خواند. ادعای اساسی کتاب من آن بود که فرایندهای نمادین از این قبیل – بازنمایی انتزاعیات، تخصیص متغیرها به نمونهها، و اعمال عملیات بر متغیرها – جزئی جداییناپذیر از ذهن انسان است. من با ذکر جزئیات نشان دادهام که مدافعان نظریهی شبکههای نورونی اغلب از این نکته غفلت میکنند و این به ضررشان تمام میشود.
صورت استدلال مطرحشده به این منظور طراحی شده بود که نشان دهد الگوهای نورونی-شبکه ای بر دو قسماند: یک دستهی “پیوندگرایی-اجرایی” که الگوهایی را شامل میشود که دارای سازوکارهایی برای تجسم صوری چگونگی عملیات بر متغیرها می باشند، و دسته ی “پیوندگرایی-حذفی” که الگوهای فاقد این سازوکارها را در بر میگیرد. الگوهایی که موفق به دریافت حقایق مختلف (اساس مربوط به زبان انسانی) شدند، همان الگوهایی بودند که دارای سازوکارهای تجسمی بودند. و آن دسته از الگوها که چنین سازوکارهایی نداشتند در این امر ناکام ماندند. همچنین به قواعدی در این الگوها اشاره کردم که اجازه ی تعمیم آزادانه ی کلیات را میدهند، در حالی که پرسپترون[24] های چندلایهای، برای شبیهسازی روابط کلی به نمونههای بزرگی نیاز دارند. این موضوعی است که در کتاب اخیر بنگیو در مورد زبان هم مطرح میشود.
هنوز هیچکس نمیداند که مغز چگونه اموری همچون عملیات بر متغیرها یا الصاق متغیرها به مقادیر نمونههایشان را انجام میدهد، اما شواهد متقنی (که در کتاب مذکور هم مورد بازبینی قرار گرفتهاند) وجود دارند که نشان میدهند مغز قادر به انجام چنین کاری هست. تقریبا همگان در این مورد اتفاق نظر دارند که حداقل تعدادی از افراد هنگامی که مشغول انجام محاسبات ریاضی یا منطق صوری هستند، به این کار دست میزنند و اغلب زبانشناسان این نکته را میپذیرند که ما در فهم زبان هم چنین عملی انجام میدهیم. پرسش واقعی این نیست که آیا مغز انسان اصولاً قادر به دستکاری نمادها هست یا نه، بلکه این است که محدودهی فرایندهایی که این عمل را انجام میدهند تا چه حد وسیع است.
هدف ثانویه از نوشتن کتابم این بود که نشان دهم ساختن مبناهای دستکاری نماد با استفاده از نورونها به عنوان عناصر کاربردی، عملا امکانپذیر است. در آن کتاب چند ایدهی قدیمی از جمله الصاق فعال از طریق نوسان موقت را توضیح دادهام؛ و همچنین شخصاً رویکردی شکافی-پرکنندهای[25] بنیان گذاشتهام که شامل استفاده از مخازنی از واحدهای گرهمانند به همراه تعدادی کُد بود، چیزی مثل کُد ASCII. شبکههای حافظه و برنامهنویسی تمایزپذیر کارهایی انجام دادهاند که قدری به آن رویکرد شباهت دارد. آنها از کدهایی مدرنتر (تعبیهای) استفاده میکنند اما از اصول مشابهی پیروی مینمایند و رویکردهایشان شامل دستکاری نمادها از طریق عملیاتهایی ریزپردازندهمانند است. من با خوشبینی محتاطانهای امیدوارم که این رویکرد در مورد موضوعاتی همچون استدلال و زبان (وقتی بتوانیم یک پایگاه دادهی تفسیرپذیر توسط ماشین بسازیم که از یکپارچگی کافی برخوردار بوده و حاوی نوعی عقل سلیمِ احتمالگرایانه اما انتزاعی باشد) بهتر عمل کند.
فرقی نمیکند در مورد مغز چه نظری داشته باشیم، چون عملاً تمامی نرمافزارهای جهان برپایهی نماد عمل میکنند. برای مثال هر سطر از کدهای کامپیوتری در حقیقت توصیفیست از مجموعهای از عملیاتها در قالب متغیرها: اگر x بزرگتر از y باشد، Pرا انجام بده، در غیر این صورت Q را انجام بده؛ A و B را با هم زنجیر کن تا چیزی جدید بدست بیاید و الی آخر. شبکههای نورونی قادرند (بر حسب ساختارهایشان و این که آیا چیزی دارند که بتوانند با آن عملیاتهای انجام شده بر متغیرها را تجسم کنند)، یک پارادایم اساساً متفاوت را بدست میدهند و مشخصاً برای انجام تکالیفی مانند تشخیص گفتار مناسباند، تکالیفی که دیگر کسی آنها را با مجموعهای از دستورها انجام نمیدهد و نباید هم بدهد. اما هیچکس یک جستجوگر نمیسازد که مبتنی بر یادگیری تحت نظارت باشد و بر اساس مجموعه ای از دروندادها (گزارشهای ضربهکلیدهای کاربر) و برونداد (تصاویر ظاهر شده بر صفحه یا بستههای دانلودی) عمل کند. لکن برداشت من از صحبت این است که در هوش مصنوعی فیسبوک، بسیاری از کارها توسط شبکههای نورونی انجام میشود، اما قطعاً اینطور نیست که کل ساختار فبسبوک بدون رجوع به دستکاری نمادها پیش برود.
و علیرغم اینکه نمادها شاید دیگر جایی در تشخیص گفتار نداشته باشند و قطعاً به تنهایی قادر به شناخت و ادراک نیستند، مسائل بسیاری وجود دارد که میتوان به سودمندی آنها در حلشان امید بست، از جمله مسائلی که هیچکس – چه در حیطهی دستکاری نمادمحورِ هوش مصنوعی کلاسیک و چه در عرصهی یادگیری عمیق – هنوز جوابی برایشان ندارد. این مسائل شامل استدلال و زبان انتزاعی هستند، عرصههایی که ابزارهای منطق صوری و استدلال نمادین برای کاربرد در آنها ابداع شده است. هر کسی که به طور جدی برای شناخت موضوعاتی همچون استدلال وابسته به عقل سلیم در تلاش باشد، این را بدیهی مییابد.
بله، بنیانگذاران یادگیری عمیق تا حدی بخاطر دلایل تاریخی که به نخستین روزهای پیدایش هوش مصنوعی بازمیگردد، اغلب نسبت به جای دادن این سازوکارها در الگوهایشان مخالفت عمیقی ابراز میکنند. مثلا هینتون در سال 2015 در استنفورد یک سخنرانی با عنوان نمادهای اثیری ارائه داد و در آن کوشید تا استدلال کند که تصور استدلال با نمادهای صوری «به اندازهی باور به این موضوع که پرتوهای نور تنها از طریق آشوبیدن اثیر نورانی قادر به جابجایی در فضا هستند، اشتباه است».
تا جایی که من مطلعم (من در سالن سخنرانی حاضر بودم) هینتون هیچ استدلالی برای این گفته ارائه نداد. اما (به باور من) این تصور برای حضار پدید آمد که او به چگونگی تجسم مجموعههای سلسلهمراتبی نمادها در بُردارها اشاره میکند. ولی این کار باعث “اثیری” شدن نمادها نمیشود – بلکه باعث میشود به شکل عناصری کاملاً واقعی در بیایند که کاربرد به خصوصی دارند و این نقض موضعی است که به نظر میآمد هیلتون در دفاع از آن سخن میگفت. (و وقتی از او خواستم که این مبحث را روشنتر بیان کند، از انجام این کار طفره رفت). از یک دیدگاه علمی (در تقابل با دیدگاهی سیاسی)، مسئله آن چیزی که ما سیستم هوش مصنوعی نهایی میخوانیم نیست. بلکه این است: این سیستم چطور کار میکند؟ آیا مبناهایی دارد که به شکل مدلهای پیادهسازیشدهی دستگاهِ دستکاری نماد عمل میکنند (چنانکه کامپیوترهای امروزی انجام میدهند)، یا بر مبنای کاملاً متفاوتی عمل میکند؟ گمان من آن است که پاسخ، هردو خواهد بود: شماری – اما نه همهی – اجزای هر سیستم هوش مصنوعی، بطور کامل به مبناهای دستکاری نمادها مشابهت دارند اما سایر اجزاء اینگونه نیستند.
این در حقیقت دیدگاهی کاملاً میانهروانه است و هر دو طرف را بر حق میداند. اما شرایطی که اکنون در آن قرار داریم به گونهای است که بخش اعظم دستاندرکاران حوزهی یادگیری عمیق مایل نیستند به صراحت عبارات نمادین (مثل “سگها بینیهایی دارند که با آن چیزها را بو میشکند”) یا عملیات بر متغیرها (مثل الگوریتمهایی که بررسی میکنند آیا P، Q، و R و استلزامات آنها بطور منطقی سازگار هستند یا نه) را در الگوهای خود جای دهند.
اغلب محققان کار با بردارها را راحتتر مییابند و هر روز در بکارگیری آن بردارها پیشرفتهای بیشتری میکنند؛ عبارات و عملیاتهای نمادین در جعبهابزار اکثر محققان جایی ندارد. اما پیشرفتهایی که آنها با کاربرد این نوع ابزارها به ثبت میرسانند تا حدی پیشبینیپذیرند: مثلاً دفعات آموزش برای یادگیری مجموعهای از برچسبها برای دروندادهای ادراکی رفتهرفته کاهش یافته و صحت طبقهبندی تکالیف افزایش مییابد. حوزههایی که پیشرفت کمتری در آنها رخ میدهد نیز به همین اندازه پیشبینیپذیرند. در حوزههایی همچون استدلال و ادراک زبان – دقیقاً همان حوزههایی که بنگیو و من سعی داریم توجهات را به آنها جلب کنیم – یادگیری عمیق به خودی خود نتوانسته کاری از پیش ببرد، حتی با میلیاردها دلار سرمایه گذاری.
به نظر میرسد موضوع اساسی در این حوزهها، تجمیع افکار پیچیده باشد و ابزارهای هوش مصنوعی کلاسیک کاملاً برای انجام چنین تکالیفی مناسب به نظر میآیند. پس چرا باید همچنان آنها را نپذیریم؟ اصولاً نمادها همچنین شیوهای برای ترکیب کردن کل دانش متنی موجود در جهان، از ویکیپدیا گرفته تا کتابهای درسی را در اختیار ما قرار میدهند؛ یادگیری عمیق هیچ سازوکار مشخصی برای یکپارچهسازی حقایق ابتدایی همچون “سگها بینی دارند” نداشته و فاقد سازوکار لازم برای اندوختن این دانش در قالب استنباطهای پیچیدهتر میباشد. اگر رؤیای ما ساختن ماشینهایی باشد که با خواندن ویکیپدیا چیزهایی یاد بگیرند، باید کار را از بستری شروع کنیم که با دانش موجود در ویکیپدیا سازگار باشد.
مهمترین پرسشی که من بهشخصه در بحث توییتری ماه گذشته در باب یادگیری عمیق مطرح نمودم در نهایت این است: آیا یادگیری عمیق میتواند مسئلهی هوش عمومی را حل نماید یا صرفاً قادر به حل مسائلی است که طبقهبندی ادراکی را شامل شوند یا چیزی میان این دو؟ چه چیز دیگری مورد نیاز است؟
نمادها نمیتوانند به تنهایی کاری از پیش ببرند و یادگیری عمیق هم قادر به انجام چنین کاری نیست. ادغام این دو و پدید آوردن آمیزههایی جدید باید از مدتها پیش شروع میشد.
درست پس از آنکه اولین پیشنویس مقاله ی حاضر را به اتمام رساندم، مکس لیتل[26] توجهم را به یک مقالهی جدید و تفکر برانگیز جلب کرد که توسط مایکل الکورن[27]، آن نگوین[28] و همکاران نوشته شده و بر خطرات اتکای بیش از حد بر یادگیری عمیق و بزرگ داده تأکید میکند. آنها بطور خاص نشان میدهند که شبکههای یادگیری عمیق متداول، معمولا هنگامی که با محرکهای معمولی روبرو میشوند که در فضای سهبعدی تغییر جهت داده باشند و در جایگاههای نامتعارفی قرار گرفته باشند، دچار مشکل میشوند. همانطور که در بخش بالا و سمت راست این تصویر ملاحظه میکنید، یک اتوبوس مدرسه به اشتباه یک برفروب تشخیص داده شده است:

زمانی که یک دسته خطای سیستماتیک شگفتآور و واضح در یک رشتهی سالم و شکوفا، رخ میدهد همهچیز متوقف میشود، افراد به تکاپو میافتند و به دنبال علت خطا میگردند. اشتباه گرفتن یک اتوبوس مدرسهی چپ شده یک خطای ساده نیست، بلکه یک خطای فاحش است. چنین خطایی نشان میدهد که نه تنها سیستمهای یادگیری عمیق ممکن است گیج شوند، بلکه ممکن است در ایجاد یک تمایز که همهی فلاسفه در موردش آگاهی دارند به مشکل بر بخورند: تمایز میان خصوصیاتی که صرفا وابستگیهایی مشروط هستند (معمولاً وقتی برفروبی در کار باشد برف هم هست، اما ضرورتاً اینطور نیست) و خصوصیاتی که کیفیات ذاتی مقولهی مورد نظر محسوب میشوند (ماشینهای برفروب در شرایط عادی میبایست زائدههایی برای برفروبی داشته باشند، مگر آنکه این زائدهها کنده شده باشد). پیش از این هم نمونههای مشابهی در زمینهی محرکهای ساختگی مشاهده کردهایم، مثلا توپ بیسبالی که آنیش آتالی[29] با دقت با استفاده از پرینت سه بعدی طراحی کرد و آن را به کف آغشته نمود. این توپ به اشتباه اسپرسو تشخیص داده شد:

نتایج تحقیقات الکورن – برخی از تصاویری که او بکار برده بود، عکسهایی واقعی از جهان طبیعی بودند – قاعدتاً میبایست نگرانیهای در رابطه با این نوع نابهنجاری را به حداکثر خود میرساندند.
اما واکنش اولیه تکاپو برای رفع مشکل نبود – بلکه غفلت هرچه بیشتر بود. چنانکه در توییتی از لکن میخوانیم که او شکاکانه محرکهایی که جایگاههایی غیر متعارف دارند را با نقاشیهای پیکاسو قیاس میکند. خواننده میتواند خودش قضاوت کند، اما باید توجه داشت که تصاویر ردیف سمت راست، همگی عکسهایی طبیعی را نشان میدهند که نه رنگآمیزی شده و نه مورد پردازش قرار گرفتهاند. این تصاویر ساختهی تخیل نیستند، بلکه نمودهاییاند از یک محدودیت واقعی که میبایست با آن روبرو شد.
به قضاوت من یادگیری عمیق به مرحلهی حسابکشی رسیده است. و مشکل آنجاست که شماری از مطرحترین رهبران این عرصه خود را به نادانی زدهاند.
این موضوع مرا به مقاله و نتیجهگیری الکورن رهنمون میسازد که حقیقتاً بطور کامل درست به نظر میآید و تمام افراد دستاندرکار این رشته باید به آن توجه کنند: “DNN [شبکه نورونی عمیق]های روزآمد، عمل طبقهبندی تصاویر را بخوبی انجام میدهند اما هنوز فاصله ی زیادی با تشخیص اشیاء حقیقی دارند.” به گفتهی نویسندگان مقاله، “ادراک DNNها از اشیائی همچون اتوبوس مدرسه و ماشین آتشنشانی کاملاً خام است” – این بسیار شبیه به نظری است که من 20 سال پیش در مورد الگوهای نورونیِ زبان مطرح کردم و به این نکته اشاره کردم که مفاهیم اکتساب شده توسط شبکههای متناوب ساده، مفاهیمی بسیار سطحی اند.
اما نکته ی فنی که میتوان از نتایج تحقیقات اخیر الکورن و همکاران آموخت چیست؟ به گفته ی الکورن و همکاران:
ممکن است شبکه های نورونی عمیق در تعمیم به دروندادهای خارج از توزیع، از جمله دروندادهای طبیعی و غیر رقیب که در محیط هایی که در زندگی واقعی با آنها روبرو میشویم متداولند شکست بخورند.
جالب است که آنها به این نکته اشاره کردهاند. در سال 1998، اصلیترین انگیزهای که من برای استفاده از دستکاری نمادها بر شمردم آن بود که پس-انتشار (که در آن زمان در الگوهایی با لایه های کمتر به کار میرفت و از این رو از اسلاف یادگیری عمیق به شمار میرود) در تعمیم به خارج از فضای نمونههای آموزشی با دشواری روبرو میشود.
و این مشکل هنوز سر جای خود باقیست.
این در حالیست که قرار بوده تشخیص شئ یکی از نقاط قوت یادگیری عمیق باشد. اگر یادگیری عمیق نمیتواند اشیاء را در جایگاههای غیرمتعارف تشخیص دهد، پس چرا باید از آن انتظار داشته باشیم بتواند تکلیف پیچیدهای مثل استدلال روزمره را انجام دهد، تکلیفی که در انجامش هیچ مهارتی هم از خود نشان نداده است؟
در واقع، جا دارد نتیجهگیری هایی که من در سال 1998 ارائه کردم را با تفصیل بیشتری مورد بازبینی قرار دهیم. بخشی از نتیجهگیری من در آن زمان بدین شرح بود (از استدلال مختصر پایانی نقل قول میکنم):
انسانها قادر به تعمیم طیف وسیعی از کلیات به نمونههای جدید دلبخواهی هستند و به نظر میرسد در بسیاری از حیطههای زبان (از جمله صرف، نحو و گفتار) و تفکر (از جمله استنتاج متعدی، استلزامات، و روابط طبقه شمول) این عمل را انجام میدهند.
هواداران دستکاری نمادها فرض میکنند که ذهن، سازوکارهایی برای دستکاری نماد شامل نمادها، طبقات و متغیرها دارد و همچنین سازوکارهایی برای تخصیص نمونهها به طبقات و بازنمایی و تعمیم روابط بین متغیرها را نمونهسازی میکند. مفروضهی فوق، ساختاری صریح و واضح را برای درک چگونگی تعمیم یافتن کلیات به نمونههای جدید دلبخواهی به دست میدهد.
الگوهای حذفی- پیوندگرای کنونی، بردارهای درونداد را با استفاده از الگوریتم پس انتشاری (یا یکی از متغیرهای آن) به بردارهای برونداد متصل مینماید.
به منظور تعمیم کلیات به نمونههای دلبخواهی جدید، این الگوها نیازمند تعمیمدهی به خارج از فضای آموزشی هستند.
این الگوها قادر به تعمیمدهی به خارج از فضای آموزشی نیستند.
بنابراین، الگوهای حذفی-پیوندگرای کنونی قادر به تشریح آن دسته از پدیدههای شناختی نمیباشند که در برگیرندهی کلیاتی هستند که میتواند آزادانه به موارد دلبخواهی تعمیم یابد.
مقالهی اخیر ریچارد اوانز[30] و ادوارد گرفنستت[31] در deep mind که بر اساس پست وبلاگی جوئل گروس[32] در مورد بازی Fizz-Buzz نوشته شده نیز استدلال به طورقابلملاحظهمشابهی را پی میگیرد و به این نتیجه میرسد که یک شبکهی متعارف و چندلایهای به تنهایی قادر به حل یک بازی نبوده است “چون قواعد عمومی لازم و قابل سنجش به صورت عام، برای فهم این تکلیف را در نیافته بود” – دقیقاً همان چیزی که من در 1998 گفتم.
راه حل آنها چیست؟ یک الگوی مختلط که عملکردی بسیار بهتر از عملکرد یک شبکهی عمیق به تنهایی داشت. الگویی که هم پسانتشار و هم (ویرایشهای مستمری از) مبناهای دستکاری دادهها، شامل متغیرهای واضح و عملیات بر متغیرها را در بر میگرفت. این واقعا تأملبرانگیز است. اینجا همان جایی است که همهی ما باید به آن چشم بدوزیم: گرادیان[33] نزولی به علاوه ی نمادها، و نه گرادیان نزولی به تنهایی. اگر میخواهیم دیگر برفروبها را با اتوبوسهای مدرسه اشتباه نگیریم، باید بالأخره رهسپار مسیر واحدی شویم، چراکه مسئلهی بنیادین مسئلهای واحد است: در تکتک جنبه های ذهن، حتی در بینایی، ما متناوباً با محرکهایی مواجه میشویم که خارج از حوزهی آموزشی قرار دارند؛ وقتی چنین اتفاقی میافتد یادگیری عمیق متزلزل میشود و برای همین هم به ابزارهای دیگری برای کمک نیازمندیم.
همه ی حرف من این است که به P ها (و Q ها) یک فرصت بدهیم.
گری مارکوس مدیر و بنیانگذار یک کمپانی یادگیری ماشینی با عنوان هوش هندسی (تحت تملک اوبر)، استاد روانشناسی و علوم عصبشناسی در دانشگاه نیویورک و همکار غیر دائم نشریات نیویورکر و نیویورک تایمز است.
[1] Gary Marcus [2] Deep learning [3] Steven Pinker [4] Yan LeCun [5] Jeff Dean [6] Judea Pearl
[7] Yoshua Bengio [8] Technology Review [9] Bayesian [10] Neuromorphic [11] Brandon Lake
[12] Marco Baroni [13] Andrew Ng [14] Jeremy Howard [15] Kaggle [16] Tom Dietterich [17] Geoffrey Hinton
[18] Nature [19] Algebraic Mind [20] Allen Newell [21] Herb Simon [22] binding [23] operation [24] perceptron
[25] Slots and fillers [26] Max Little [27] Michael Alcorn [28] Anh Nguyen [29] Anish Athalye [30] Richard Evans
[31] Edward Grefenstette [32] Joel Grus[33] gradient

پیشنهاد کتاب
-

مجله سفید ۳: پریزدگی
-
مجله سفید ۱: هیولاشهر
-
دختری که صورتش را جا گذاشت
-
گریخته: هفتروایت در باب مرگ




آخرین دیدگاهها
-

بی نظیر.
-
قابل تامل و لذتبخش بود
نظر خود را بنویسید:
پیشنهاد کتاب
-
مجله سفید ۳: پریزدگی
-
مجله سفید ۱: هیولاشهر
-
دختری که صورتش را جا گذاشت
-
گریخته: هفتروایت در باب مرگ